

How Can You Check To See If You Are Blocked From Registering Your Vehicle If You Have Unpaid Tolls
How to encounter locked HTML code, how to bypass social content lockers and other website info gathering countermeasures
Is it possible to protect the HTML code of a web page?
The source code of the spider web folio cannot be protected from viewing. It is a fact. Only you can make code analyzing task more difficult. Completely inefficient methods include locking the right mouse button. The more effective means include obfuscation of the code. Particularly if the code is not nowadays in the source text of the page, but is loaded from unlike files using JavaScript and if at unlike stages (JavaScript and HTML itself) are also obfuscated. In this example, everything becomes much more than hard. But such cases are quite rare – more than oft found on the websites of very large companies. We will consider simpler options.
How to view the source HTML code of a web page if the right mouse push and CTRL+u are locked
If the right mouse push does not piece of work, then just printing CTRL+u. I came across a site where CTRL+u also refused to work:
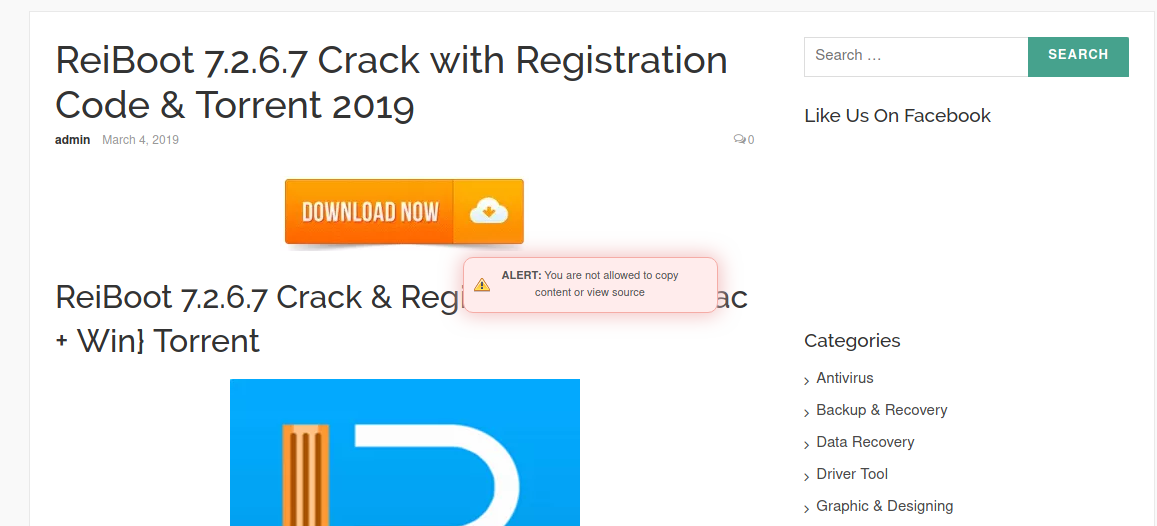
CTRL+u can be disabled using JavaScript. That is, the first selection is obvious – with disabled JavaScript the source code will non exist "locked".
Another option is to detect the option "Show source lawmaking" in the browser bill of fare. In Firefox, this pick is there, only personally information technology always takes me a lot of fourth dimension to find it))) In Chrome, I can't find this option at all in the browser menu, so remember the line
view-source:
If this line is added earlier whatsoever address of the site and all this is inserted into the tab of a spider web browser, the source lawmaking of this page will be opened.
For example, I desire to come across the HTML of the https://suip.biz/?act=view-source folio, then I insert the line view-source:https://suip.biz/?act=view-source in the tab web browser and get the source lawmaking in information technology.
By the style, if it'southward hard for y'all to remember the view-source, and then hither's the appropriate service: https://suip.biz/?human activity=view-source (don't laugh at its "complexity" - none can remember everything in life, and sometimes information technology'southward actually easier to open such page and utilize it to get the cord you need to view the source code).
By the way about disabling JavaScript – it is not necessary to climb into the 'deep' browser settings and look for where this option is. You even do not demand to disable JavaScript, it is plenty to pause the execution of scripts for a specific page.
To exercise this, press F12, then in the developer tools, go to the Sources tab and click there F8:
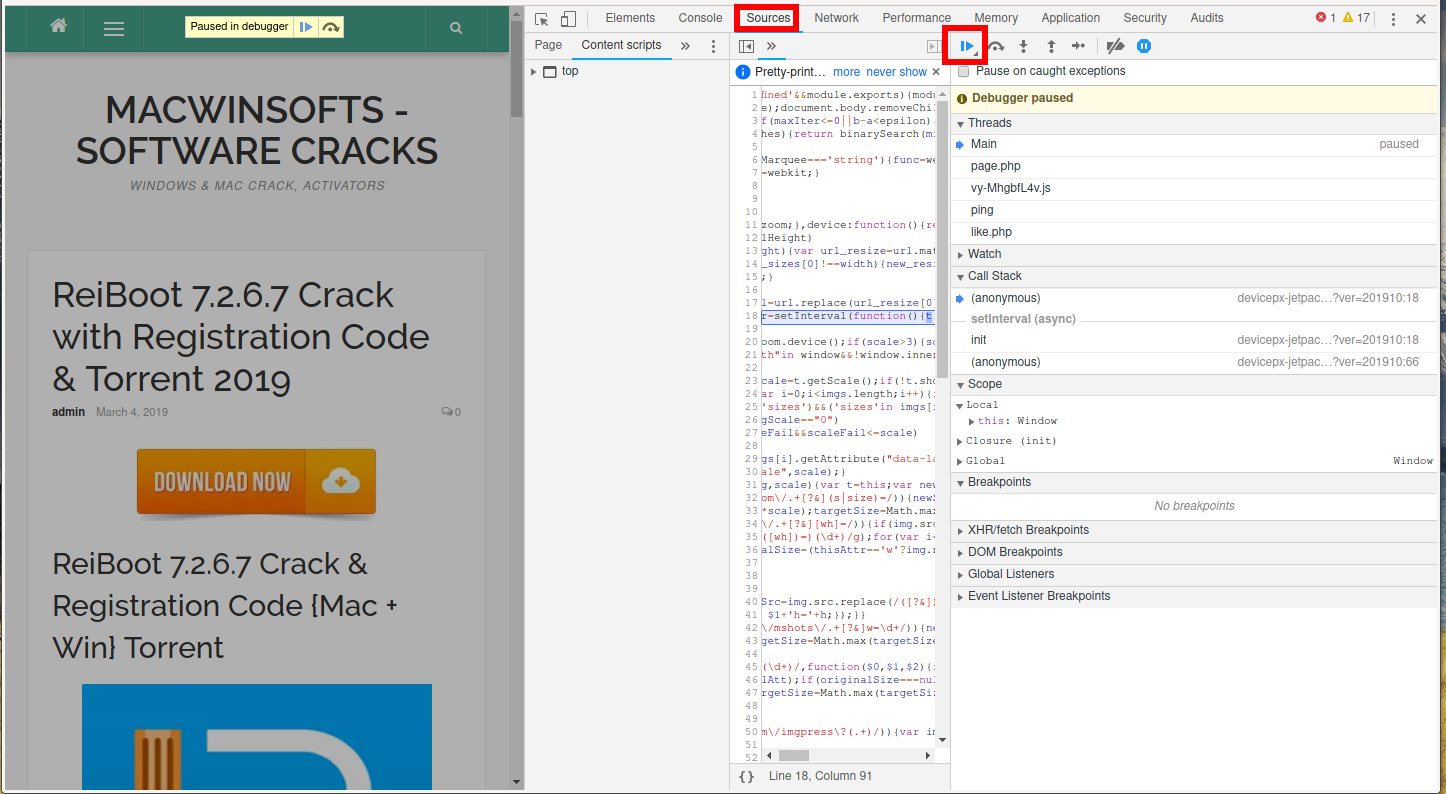
At present the CTRL+u key combination will work on the site folio, every bit if it has never been disabled.
Bypassing social content lockers
The social content lockers looks like this:
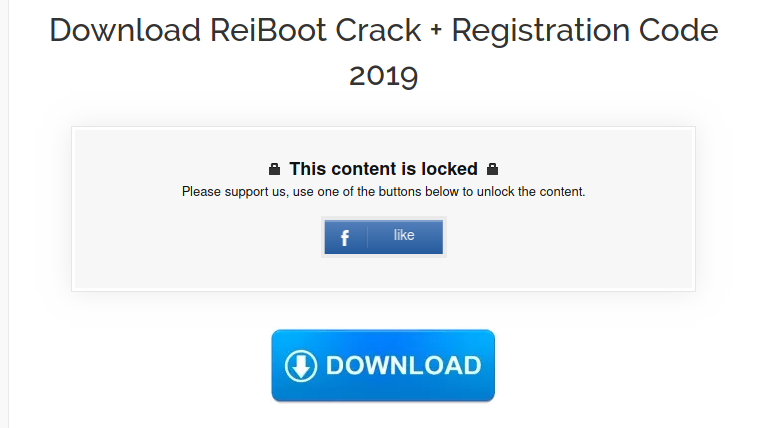
The point is the following, to view the content, you need to 'like' this article on the social network.
"Nether the hood" there is everything (unremarkably) like this: "hidden" text is already present in the HTML page, but is subconscious with the manner property style="brandish: none;". Therefore, information technology is enough:
- open the HTML folio protected by social content lockers
- discover all occurrences style="brandish: none;" - usually they are not very many.
An example of "hacking" a social content lockers:
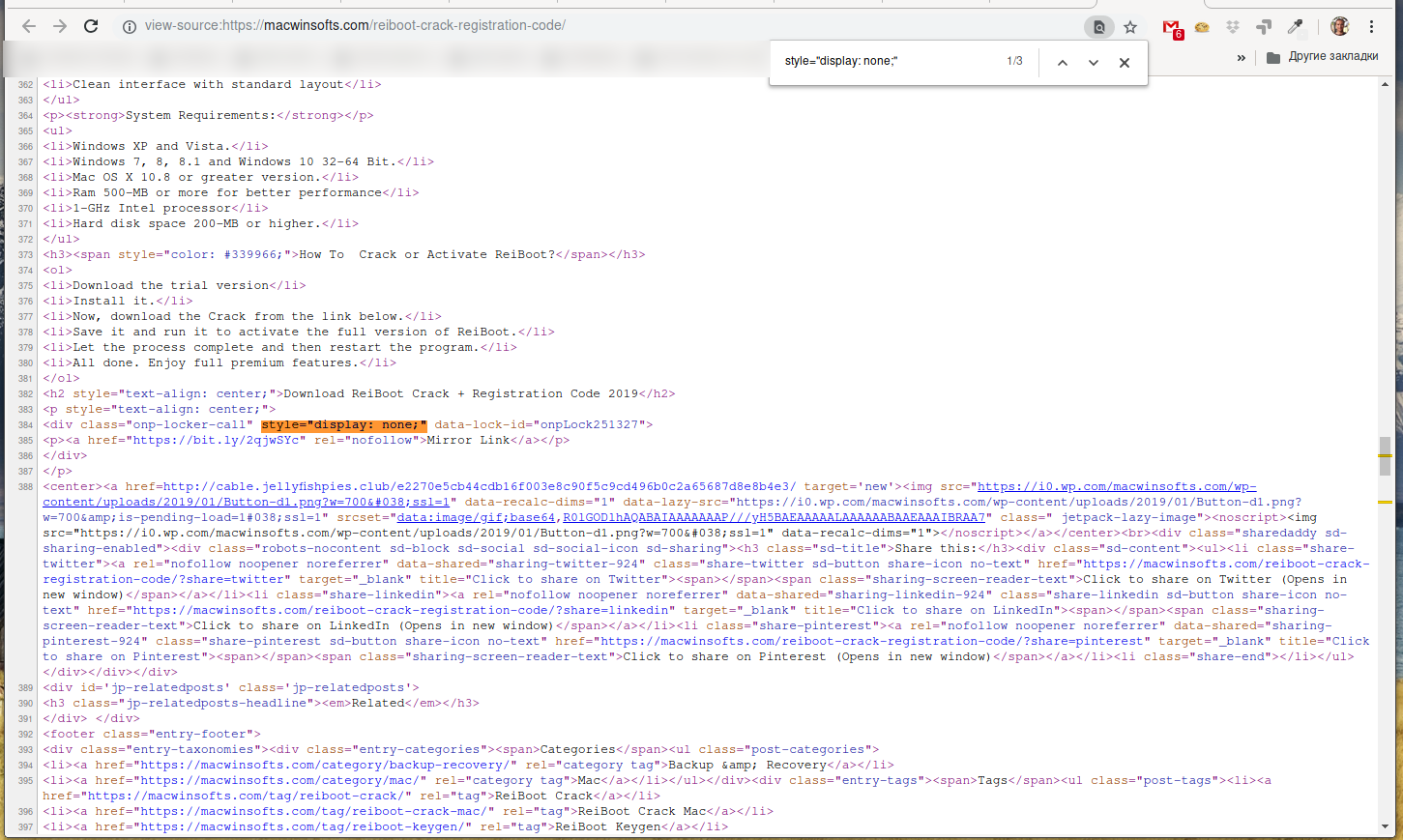
Hidden text:
<p manner="text-align: center;"> <div class="onp-locker-call" style="display: none;" data-lock-id="onpLock251327"> <p><a href="https://bit.ly/2qjwSYc" rel="nofollow">Mirror Link</a></p> </div> </p>
Merely every time information technology's not very user-friendly to climb into the source code, and I … fabricated an online service that itself retrieves information subconscious by social blockers for you lot, its address: https://suip.biz/?act=social-locker-cracker
It is able to bypass four social content lockers and got a "heuristic" analysis – it turns on if no upshot plant, and so information technology displays the contents of all blocks with mode="display: none;".
Past the way, if you run into pages that this service cannot bypass – just write a link to the problem page in the comments – I volition add together the appropriate 'handler'.
The site that I testify in the screenshots seems to spread counterfeit software. I looked at the links with the assist of the cracker of social content lockers – it turned out that all the hidden links are absolutely non-bonded: they pb to the demo version of the programs or to the official website. In some articles there are no links at all. I was interested in such "marketing" and I decided to search other sites of the same author.
Search for faux pirate sites
On the "Checking if the site uses CloudFlare" service, we check:
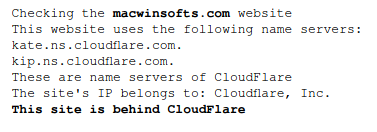
This site is behind CloudFlare – Ha ha, classic!
We look at the history of the IP domain on securitytrails: https://securitytrails.com/domain/macwinsofts.com/history/a
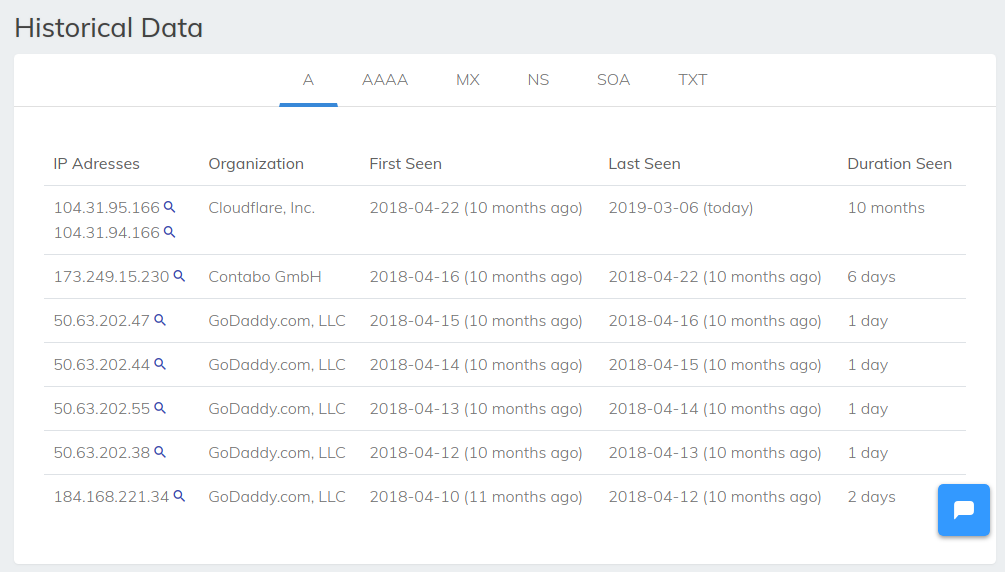
We see there:
- Cloudflare, Inc. - these are today's IP addresses
- GoDaddy.com, LLC - auction, domain parking and the like
- Contabo GmbH - quite possible existent hosting where this site is located
So, it is likely that the IP of this site is 173.249.15.230. At present, at that place is no information on the associated sites on the securitytrails for this IP.
Therefore, we go to the "List of sites on 1 IP" service, enter 173.249.15.230 every bit source data and get at that place:

List:
- haxsofts.com
- crackways.com
- crackmafia.org
All sites have a similar modus operandi, everywhere there is a social content locker, everywhere instead of a pirate links there are links to the demo version, links to official sites, or there is simply nothing under the locked content.
Site IP Verification with curlicue
For IP verification, I unremarkably utilise the following command:
roll -v 173.249.15.230 -H 'Host: SITE_ADDRESS'
For example:
whorl -5 173.249.fifteen.230 -H 'Host: macwinsofts.com'
Or and then, if you need to check the site on the HTTPS protocol:
curl -5 https://173.249.15.230 -H 'Host: macwinsofts.com'
But server 173.249.xv.230 is configured then that absolutely any host, even if y'all write "dfkgjdfgdfgfd" at that place, it redirects to the accost with HTTPS, that is, to "https://dfkgjdfgdfgfd". And the server itself does non accept requests via HTTPS at all – the web server is non configured to procedure them and port 443 is not fifty-fifty open.
In principle, information technology tin can exist proved indirectly that this server is configured to process the macwinsofts.com host, for example, this asking almost instantly causes an error 503:
curl -5 173.249.15.230/wp-content/uploads/2018/10/ReiBoot-Crack-Mw.png -H 'Host: false.com'
But this request, although it will also crusade an error 503, but will force the server 'to call back' for a long time:
curlicue -five 173.249.15.230/wp-content/uploads/2018/x/ReiBoot-Crack-Mw.png -H 'Host: macwinsofts.com'
Apparently, there, due to the peculiarities of the settings, endless redirects occur and in the end the connexion is reset on timeout.
This method allows including brute-forcefulness files and folders:
curl -v 173.249.xv.230/.htaccess -H 'Host: macwinsofts.com'

And quite an interesting event is such a query:
scroll -v 173.249.15.230/wp-content/uploads/2018/10/ReiBoot-Crack-Mw.png -H 'Host: ya.com'
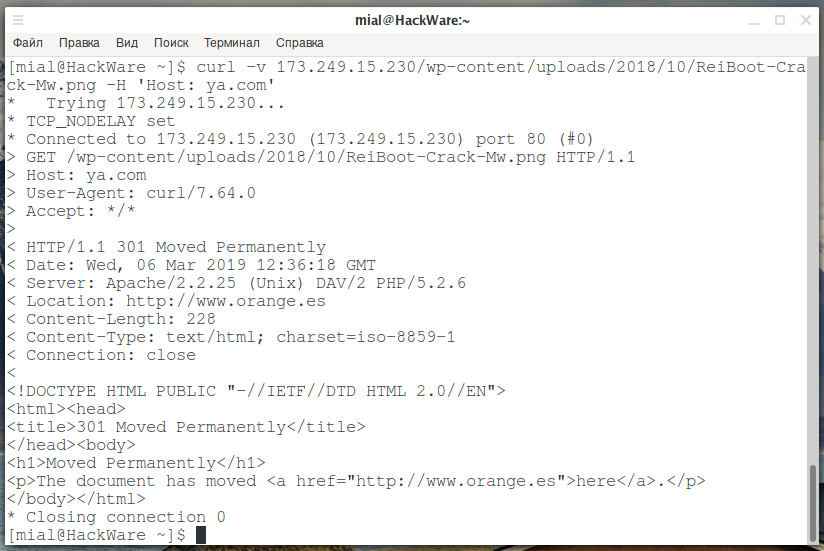
Conclusion
What is the meaning of these sites? Some of them accept .exe files for download – peradventure viruses or some dubious monetization. Although I checked on virustotal – like, the file is not malicious. Those sites that do not have executable files for download, apparently waiting for the growth of traffic, to then begin to distribute this executable file.
Perhaps the owner expects an increase traffic to enable monetization or to spread viruses.

Source: https://miloserdov.org/?p=2730
Posted by: greenabrount1980.blogspot.com
0 Response to "How Can You Check To See If You Are Blocked From Registering Your Vehicle If You Have Unpaid Tolls"
Post a Comment